在云原生和微服务架构日益普及的今天,传统的日志系统(如 ELK Stack)虽然功能强大,但其资源消耗高、部署复杂和成本高昂的问题也逐渐显现。Grafana Loki 应运而生,作为一款受 Prometheus 启发的轻量级日志聚合系统,它旨在以极低的资源开销实现高效的日志收集、索引和查询。本文将通过图解的方式,深入剖析 Loki 的工作架构、数据处理流程以及其创新的存储服务设计。
一、核心设计理念:不为日志内容索引,只为日志标签索引
Loki 最核心的设计理念与 Prometheus 一脉相承:只对日志的元数据(即标签)建立索引,而不对日志内容本身进行全文索引。日志内容本身以压缩块的形式原样存储。这种设计带来了革命性的优势:
- 成本极低:索引体积大幅缩小(通常只有日志数据体积的1%到2%),存储和查询成本显著下降。
- 运维简单:架构简洁,组件少,与 Prometheus、Grafana 生态无缝集成。
- 高效查询:通过标签快速缩小搜索范围,然后在范围内的日志流中进行全文搜索(Grep),非常适合基于时间范围和标签的查询模式。
二、Loki 工作架构图解
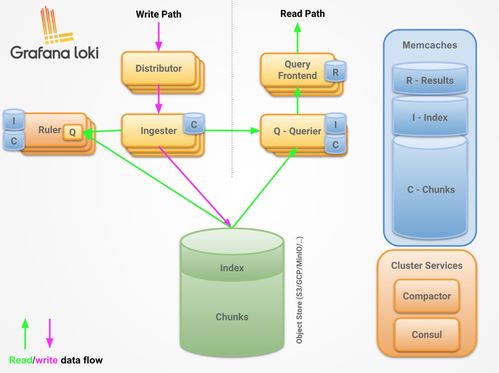
一个典型的 Loki 集群主要由三个核心组件构成,其协作关系如下图所示:
[日志生产者] (K8s Pods, 节点等)
│
▼ (通过 Promtail/Docker Driver/Fluent-bit 等推送)
[Distributor] (分发器) ─── 写入 ───> [Ingester] (摄取器) ─── 写入 ───> [存储]
│ │
└────────────────── 查询 ──────────────────────────────┘
│
▼
[Querier] (查询器) <─── [Grafana/LogCLI 用户查询]
│
└─── 读取索引 ───> [索引存储]1. Distributor(分发器)
- 职责:接收来自客户端(如 Promtail)的日志流推送请求(HTTP/HTTPS)。
- 关键处理:
- 验证:检查日志格式和标签的有效性。
- 分片:根据日志的标签集(Label Set)和哈希算法,将日志流路由到对应的 Ingester 节点,确保同一日志流的数据发送到同一个 Ingester,保证顺序性。
- 复制:根据配置的复制因子(Replication Factor),将数据复制到多个 Ingester 以实现高可用。
2. Ingester(摄取器)
- 职责:接收来自 Distributor 的日志流,在内存中构建数据块(Chunks),并定期将这些块持久化到后端存储。
- 关键处理:
- 内存缓存:日志首先被写入内存中的“尾块”(Tail Block),并响应最新日志的查询。
- 块切割:基于配置的时间间隔(如1小时)或块大小,将内存中的日志数据压缩并切割成不可变的“块”。
- 写入存储:将完整的块及其关联的索引条目(标签 -> 块引用)分别写入 对象存储 和 索引存储。
- 写入确认:只有在块被成功持久化后,Ingester 才会向 Distributor 返回成功的写入确认。
3. Querier(查询器)
- 职责:处理来自 Grafana 或 LogCLI 的日志查询请求。
- 关键处理:
- 解析查询:解析 LogQL 查询语句,提取时间范围和标签匹配器。
- 查询索引:向索引存储查询,找出在指定时间范围内、匹配标签的所有日志块(Chunks)的引用。
- 获取数据:根据块引用列表,从对象存储中并行加载这些压缩的日志块。
- 执行查询:在加载的日志数据中执行过滤(如
|= "error")和聚合操作。
- 合并结果:将从 Ingester(热数据)和存储(冷数据)获取的结果合并、排序后返回给用户。
三、数据处理流程详解
写入路径(Write Path):
1. 日志采集:客户端(如 Promtail)从文件、系统日志或容器标准输出采集日志,并附加一组标签(如 job="nginx", pod="nginx-abc")。
2. 推送与分发:客户端将日志流推送给 Distributor。Distributor 通过一致性哈希,找到目标 Ingester。
3. 内存处理:Ingester 将日志追加到对应日志流的内存块中。
4. 持久化:满足条件后,Ingester 将内存块压缩(通常使用 gzip、snappy 或 lz4),生成一个块文件,然后:
- 将该块文件上传至对象存储(如 S3、GCS、MinIO)。
- 将该块的元数据(标签、时间戳、块存储路径)写入索引存储(如 DynamoDB、Cassandra、BoltDB)。
查询路径(Query Path):
1. 接收查询:Querier 收到一个 LogQL 查询,例如 {job="api-server"} |= "timeout"。
2. 索引查找:Querier 查询索引存储,获取所有标签包含 job="api-server" 且在查询时间范围内的块引用列表。
3. 数据加载:Querier 同时执行两项操作:
- 从对象存储加载所有相关块。
- 向所有 Ingester 查询,获取尚未被持久化的“热数据”。
- 本地执行:Querier 在本地解压并遍历所有日志行,应用过滤条件(
|= "timeout")。 - 返回结果:将过滤后的日志行按时间排序,返回给前端。
四、存储服务:解耦的索引与数据存储
Loki 存储设计的精妙之处在于将索引和块数据分离,这为灵活性和成本优化提供了巨大空间。
- 索引存储(Index Storage):
- 存储内容:仅存储“标签 -> 块引用”的映射关系。这是一个键值查询,要求较高的随机读写性能。
- 可选后端:
- 单机模式:使用本地文件(如 BoltDB),简单易用。
- 微服务/集群模式:使用 NoSQL 数据库,如 AWS 的 DynamoDB、Google 的 Bigtable,或开源的 Cassandra。这些数据库擅长处理高并发的键值查询,且易于扩展。
- 块数据存储(Chunk Storage / Object Storage):
- 存储内容:存储压缩后的、不可变的日志数据块。这是一个顺序追加写、批量读取的场景。
- 首选后端:对象存储,如 Amazon S3、Google Cloud Storage (GCS)、Azure Blob Storage 或兼容 S3 的私有存储(如 MinIO、Ceph)。
- 优势:对象存储成本极低、无限扩展、持久性高,完美契合 Loki 存储大容量、低频访问日志数据的需求。
存储架构图解:`
[Loki 集群]
/ \
/ \
(索引查询/写入) (数据块上传/下载)
/ \
▼ ▼
[索引存储] [对象存储]
(DynamoDB/Cassandra) (S3/GCS/MinIO)`
五、与优势
通过以上图解与分析,我们可以看到 Grafana Loki 架构的清晰与高效:
- 面向云原生:天然支持 Kubernetes,标签模型与 Prometheus 指标完美对应。
- 成本效益:分离索引与数据,利用廉价对象存储,总拥有成本(TCO)远低于传统方案。
- 查询高效:通过标签索引快速定位,避免了不必要的大规模全文检索。
- 运维简化:组件职责单一,与 Grafana 深度集成,提供开箱即用的可视化体验。
Loki 并非要替代所有日志系统,它在处理 调试、故障排查、审计 以及需要将日志与指标、链路追踪关联的 可观测性 场景中表现出色。对于需要复杂日志分析、长期趋势报告的场景,可能仍需结合其他工具。但其创新的架构无疑为日志管理领域带来了一个极具吸引力的轻量级选择。