在计算机科学与数据处理服务领域,图(Graph)作为一种强大的非线性数据结构,被广泛应用于社交网络分析、路径规划、知识图谱、推荐系统等众多场景。图的存储效率直接影响着相关算法的性能与服务的响应能力。在众多存储方法中,邻接表法因其在处理稀疏图时的卓越空间效率与灵活性,成为了构建高效数据处理和存储服务的核心基石。
一、邻接表法的核心思想
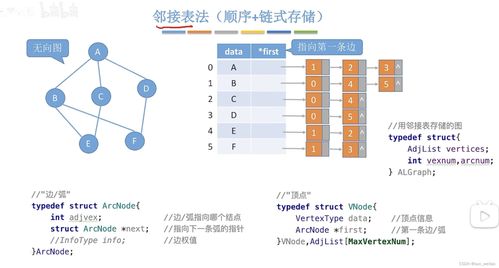
邻接表法的核心在于为图中的每个顶点(Vertex)建立一个单链表,用于存储所有与该顶点直接相连的边(Edge)。这种结构由两部分组成:
- 顶点表:一个数组(或列表),用于存储所有顶点的信息(如ID、属性数据)和一个指向其邻接链表的头指针。
- 边链表:每个顶点对应的单链表,链表中的每个节点代表一条以该顶点为起点的边,存储了该边指向的邻接顶点(及边的权重等信息)以及指向下一个邻接点的指针。
例如,对于一个无向图,边 (u, v) 会在顶点u和顶点v的邻接链表中各出现一次。
二、邻接表法在数据处理与存储服务中的优势
相比于邻接矩阵法,邻接表法在构建现代数据处理服务时展现出显著优势:
- 极高的空间效率:它仅存储实际存在的边,对于顶点数n很大但边数相对较少(稀疏图)的场景(如大多数社交网络),其空间复杂度仅为O(n+e),远低于邻接矩阵的O(n²),极大降低了存储成本,这对于云存储和分布式数据库服务至关重要。
- 高效的邻居遍历:查询一个顶点的所有邻居(或出边)非常高效,只需遍历其邻接链表即可,时间复杂度为O(该顶点的度)。这对于社交网络中的“查找好友”、推荐系统中的“协同过滤”等高频操作是理想选择。
- 动态增删灵活:在图中动态添加或删除顶点和边相对容易,通常只涉及链表的插入与删除操作,便于处理实时变化的数据流,如实时交通路况图或动态用户关系图。
- 易于集成属性:链表节点可以方便地扩展,以存储边的权重、类型、时间戳等丰富属性,满足复杂业务场景(如带权路径计算、时序关系分析)的数据存储需求。
三、服务于数据处理系统的实现与优化
在实际的大规模数据处理和存储服务中(如使用Apache Spark GraphX、Neo4j等图数据库),邻接表的实现会进行深度优化:
- 压缩存储:使用数组压缩存储边信息,以减少指针开销并提高缓存局部性。
- 分区与分布式存储:将大图的顶点和边分区后分布式存储在多台机器上,以支持海量图数据的处理。邻接表结构易于分区,例如可以按顶点ID的哈希值进行分布。
- 索引加速:除了基本的邻接链表,通常会为顶点ID或边属性建立额外的索引结构(如哈希索引、B+树),以支持快速的顶点查询或条件边遍历。
- 与计算框架结合:在像Pregel、GraphLab这样的图计算模型中,计算任务通常以顶点为中心展开,这与邻接表“围绕顶点组织边”的思想天然契合,消息可以高效地沿邻接表传递。
四、典型应用场景
邻接表法支撑了众多核心数据处理服务:
- 社交网络服务:存储用户(顶点)及关注/好友关系(边)。快速查找一度人脉、计算潜在推荐。
- 推荐系统:构建“用户-商品”二分图,通过遍历用户的邻接商品或商品的邻接用户来进行协同过滤推荐。
- 知识图谱与搜索引擎:存储实体(顶点)与关系(边),支持复杂的多跳关联查询与推理。
- 网络拓扑与路由:存储路由器/交换机(顶点)与连接线路(边),用于路径计算和故障分析。
- 地理信息系统(GIS):存储地点(顶点)与道路(边),是路径规划算法(如Dijkstra、A*)的底层数据结构。
结论
邻接表法以其高效、灵活、节省空间的特性,为处理现实世界中普遍存在的稀疏关联关系数据提供了理想的存储方案。它是构建高性能、可扩展的图数据处理与存储服务的底层支柱。理解并善用邻接表,对于设计能够应对海量复杂关系数据的现代IT服务架构具有不可替代的基础性意义。随着图计算需求的日益增长,基于邻接表及其变体的优化存储技术将继续在数据驱动的服务创新中扮演关键角色。