Apache Pulsar 是一款开源的分布式消息与流处理平台,凭借其独特的分层架构、低延迟、高吞吐量和多租户特性,已成为现代数据架构中的核心组件之一。它原生支持发布/订阅消息传递模型、队列模型以及流处理模型,集消息队列、实时流处理和存储服务于一体,为大规模数据处理提供了强有力的支撑。
一、Pulsar 核心特性与架构介绍
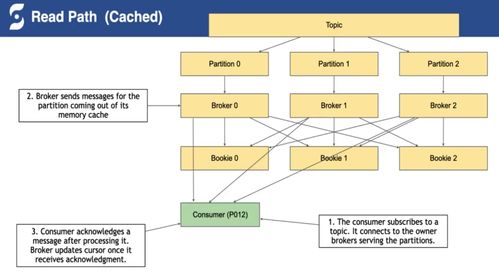
- 分层架构:这是 Pulsar 最核心的设计亮点。它将服务层(Broker) 与存储层(BookKeeper) 完全解耦。
- Broker 集群:无状态,负责消息的生产、消费、路由和服务发现。这种无状态设计使其可以轻松进行水平扩展和故障恢复。
- Apache BookKeeper 集群:提供持久化、高可用、强一致的存储服务。它将数据以日志段的形式存储在多台存储节点上,保证了数据的可靠性和可扩展性。
- 统一的消息模型:Pulsar 巧妙地通过“订阅”模式统一了流(Streaming)和队列(Queue)两种语义。生产者发布消息到主题(Topic),消费者可以创建不同类型的订阅(如独占、故障转移、共享、Key_Shared)来以不同模式消费数据,灵活应对多样化的业务场景。
- 多租户与命名空间:原生支持多租户,通过租户(Tenant)和命名空间(Namespace)进行资源隔离、配额管理和访问控制,非常适合云原生和SaaS化部署。
- 地理复制:提供跨地域的集群间数据同步功能,支持异步、同步等多种复制模式,是实现数据灾备和全球低延迟访问的关键。
- 函数计算(Pulsar Functions)与IO连接器:内置轻量级流处理框架Pulsar Functions,支持使用Java、Python、Go等语言编写处理逻辑。拥有丰富的Pulsar IO连接器生态,可以轻松与Kafka、MySQL、Elasticsearch、HDFS等外部系统进行数据集成。
二、Pulsar 部署指南
部署一个生产可用的Pulsar集群通常包含以下步骤:
1. 环境准备
- 硬件:建议至少3个节点(物理机或虚拟机),分别部署ZooKeeper、BookKeeper和Broker。生产环境建议各组件独立部署,且每个集群至少3节点以保证高可用。
- 软件:JDK 8或11,并确保节点间网络通畅,时钟同步。
2. 部署ZooKeeper集群(元数据存储)
Pulsar依赖ZooKeeper来存储集群元数据、配置和协调信息。需要部署两个ZooKeeper集群:
- 本地ZooKeeper(通常3节点):管理单个Pulsar集群的元数据。
- 配置存储ZooKeeper(通常3节点):用于跨集群的配置管理,如地理复制。
3. 初始化集群元数据
使用Pulsar自带的初始化工具,将元数据写入ZooKeeper。
4. 部署BookKeeper集群(存储层)
在所有BookKeeper节点上安装BookKeeper,并配置好存储目录(Journal目录和Ledger目录应使用不同的高性能磁盘,如SSD),然后启动服务。
5. 部署Broker集群(服务层)
在所有Broker节点上安装Pulsar Broker,配置其连接到的ZooKeeper和BookKeeper集群地址,然后启动服务。
6. 部署可选组件
- Pulsar Proxy:为客户端提供网关服务,避免客户端直接连接所有Broker。
- Pulsar Manager:提供Web UI管理界面,方便监控和管理集群。
7. 验证与配置
使用 pulsar-admin 命令行工具或客户端API创建租户、命名空间、主题,并进行生产消费测试,验证集群运行正常。同时配置配额、权限策略等。
三、作为数据处理与存储服务
Pulsar不仅仅是一个消息队列,它构建了一个完整的数据处理与存储管道。
1. 数据摄取与缓冲
Pulsar是高性能的数据总线,可以作为前端应用、IoT设备、日志流等海量数据的统一接入层。其持久化存储和低延迟特性确保了数据不丢失且能被实时消费。
2. 实时流处理
- Pulsar Functions:对于简单的ETL、过滤、聚合任务,可以直接在Pulsar集群内部署Functions,实现“原地”流处理,无需引入额外的计算框架(如Flink/Spark),简化架构。
- 与Flink/Spark集成:对于复杂的流处理任务,Pulsar可以作为Flink或Spark Streaming的可靠数据源和数据汇,通过专用的连接器实现高性能对接。
3. 分层存储与长期数据保留
这是Pulsar作为“存储服务”的核心能力。当Topic中的数据积压超过一定阈值或时间后,Broker会自动将旧的“日志段”从BookKeeper卸载到更廉价的分层存储(如AWS S3、Google Cloud Storage、HDFS)中。
- 对客户端透明:消费者需要读取历史数据时,Pulsar会自动从分层存储中取回,整个过程对应用无感知。
- 成本效益:实现了热数据(BookKeeper SSD)和冷数据(对象存储)的自动分层,在保证性能的同时大幅降低了海量数据长期保留的成本。这使得Pulsar可以充当一个无限回溯的流存储系统,支撑“流批一体”的数据湖仓架构。
4. 数据服务与共享
基于多租户和地理复制,一份数据可以被多个团队、多个地域的不同应用(如实时分析、模型训练、数据仓库导入)通过不同的订阅模式同时消费,实现数据的复用和价值最大化。
###
Apache Pulsar 以其云原生、存算分离的先进架构,将高性能消息传输、弹性流处理和高效分层存储无缝融合。从部署上看,虽然组件较多,但清晰的层次带来了极佳的运维灵活性和扩展性。在数据处理与存储场景中,Pulsar扮演了从实时数据接入、处理到长期归档的“一站式”平台角色,是构建现代实时数据管道和数据湖流存储层的理想选择。