在数据仓库的学习之旅中,理解数据存储与处理是构建高效分析平台的核心。本文将深入探讨数据仓库中数据处理与存储服务的关键概念、技术架构与实践策略。
一、数据存储:数据仓库的基石
数据仓库的存储系统是其稳定运行的物理基础,它不仅需要容纳海量数据,还需支持高效查询与分析。
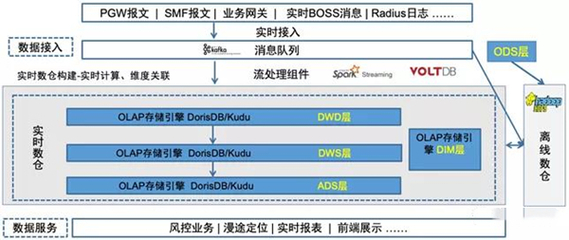
- 存储架构:通常采用分层设计,包括原始数据层(ODS)、数据仓库层(DW)和数据集市层(DM)。ODS层存储来自业务系统的原始数据,DW层进行清洗、整合与建模,DM层则面向特定业务主题提供优化后的数据。
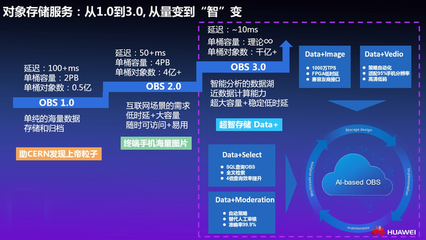
- 存储技术:传统上,数据仓库依赖于关系型数据库(如Oracle、Teradata),但随着大数据时代的到来,分布式存储系统(如Hadoop HDFS、云存储服务)因其可扩展性和成本效益而日益普及。列式存储(如Apache Parquet、ORC)因其在分析查询中的高性能而成为主流选择。
- 数据模型:星型模型和雪花模型是数据仓库中常见的数据建模方法。星型模型以事实表为中心,连接多个维度表,结构简单,查询高效;雪花模型则通过规范化维度表减少数据冗余,但可能增加查询复杂度。选择哪种模型需根据业务需求和数据特性权衡。
二、数据处理:从原始数据到洞察的转化
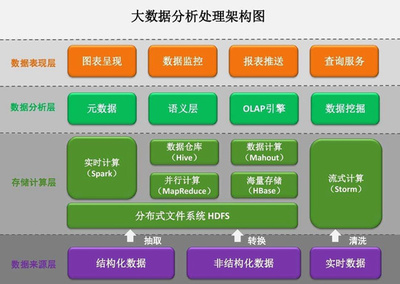
数据处理是将原始数据转化为有价值信息的关键环节,涉及数据抽取、转换、加载(ETL)或抽取、加载、转换(ELT)等流程。
- ETL/ELT流程:
- 抽取(Extract):从异构数据源(如数据库、日志文件、API)中获取数据。
- 转换(Transform):清洗数据(处理缺失值、去重)、标准化格式、进行业务逻辑计算(如聚合、关联)。
- 加载(Load):将处理后的数据导入数据仓库的存储层。ETL通常在加载前完成转换,适合结构化数据处理;ELT则先加载原始数据,在数据仓库内进行转换,更适合处理非结构化或大数据量场景。
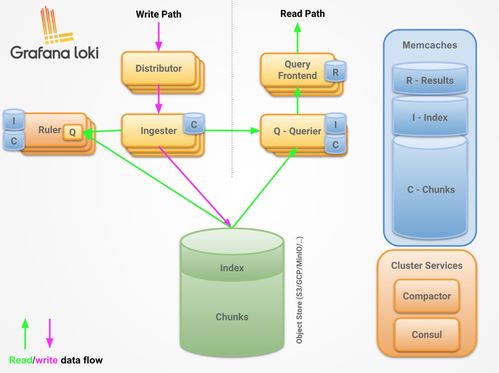
- 处理工具与技术:传统ETL工具(如Informatica、Talend)提供图形化界面,便于流程设计;现代数据平台则常采用编程框架(如Apache Spark、Flink)进行流批一体处理,支持实时与离线分析。云服务(如AWS Glue、Azure Data Factory)提供了托管的数据处理服务,简化了运维工作。
- 数据处理策略:
- 批处理:适用于非实时场景,如夜间跑批生成日报表。
- 流处理:用于实时监控或即时分析,如金融交易风控。
- 增量处理:仅处理新增或变更的数据,提升效率并减少资源消耗。
三、数据处理与存储服务的整合实践
在实际应用中,数据处理与存储服务需紧密协同,以构建灵活、可扩展的数据仓库架构。
- 云原生数据仓库:以Snowflake、BigQuery为代表的云数据仓库,将存储与计算分离,允许独立扩展存储容量和处理能力,用户按需付费,大幅提升了资源利用率。它们通常内置了数据处理功能,支持SQL直接进行复杂转换。
- 数据湖与数据仓库融合:数据湖(如基于AWS S3、Azure Data Lake Storage)存储原始多格式数据,数据仓库提供高性能查询,通过Lakehouse架构(如Databricks Delta Lake)实现统一管理,兼顾灵活性与效率。
- 自动化与运维:通过元数据管理、数据血缘追踪和自动化调度(如Apache Airflow),确保数据处理流程的可观测性与可靠性。监控存储使用情况、查询性能,并实施数据生命周期策略(如冷热数据分层、归档),以优化成本。
四、挑战与趋势
随着数据量爆发式增长,数据仓库的存储与处理面临新挑战:如何平衡性能与成本?如何保障数据安全与合规?未来趋势包括:
- 智能化:AI驱动自动优化查询与存储分配。
- 实时化:流处理技术普及,支持更快的业务决策。
- 一体化:存储、处理、分析服务进一步集成,降低使用门槛。
数据仓库的数据存储与处理服务是其价值实现的双引擎。通过合理设计存储架构、选择高效处理工具,并拥抱云原生与融合技术,企业能构建出响应迅速、洞察深入的数据分析平台,为业务增长注入持久动力。掌握这些核心知识,是每位数据从业者迈向专业化的必经之路。